[python] beautifulsoup을 이용해 네이버 뉴스 전체를 크롤링을 해보자!
(네이버 뉴스 크롤링 2)
*본 포스팅은 개인 학습용으로 만든 크롤러라 완벽한 코드가 아닌 점 알려드립니다.
오늘은 네이버 신문기사 전문 크롤링 하는 방법에 대해
포스팅을 하도록 하겠습니다!
중복설명은 최대한 안 할 겁니다.
혹시 전 포스팅을 안 보셨다면 참고 하세요~
2019/02/07 - [공부/Python] - [python] beautifulsoup을 이용해 네이버 뉴스 리스트 크롤링을 해보자!
naver 신문 기사 전체 크롤링 / 파이썬 크롤링 / 네이버 기사 전체 크롤링 / beautifulsoup 크롤링
01. 들어가기 전..
포스팅 전에 아셔야 할 것 설명해드리겠습니다.
우선 사실 이번 포스팅 안하려고 했습니다.
제가 글로서 쉽게 설명할 자신이 없고
코드가 테스트 할 때 문제점이 좀 있는데 원인을 알 수 없어서 계속 미루고 있었는데,
필요하신 분들도 있으시고 왜 안되는지 원인도 이제 알게 되어서,
오늘 날 잡아서 포스팅합니닷!
우선 저는 처음 크롤링 코드 만들때 (저번 네이버 뉴스 리스트만 크롤링하는 코드)
네이버 기사의 전문을 긁어오는 것은 불가능 하다고 생각했습니다.
왜냐면
네이버 검색창에 검색어를 입력하고 관련 기사들을 눌러보시면 아시겠지만
각기 다른 신문사 사이트로 들어가서 기사를 볼 수 있죠.
예를 들어 조선일보 , 데일리팜 , 한겨례 등등 그들은 완전 별개의 신문사들이고 홈페이지 html구조도 다 다릅니다.
이 말인 즉슨 각 신문사 마다 html tag의 id값이나 class값이 달라서
크롤러를 만들려면 신문사 마다 크롤러를 변경해줘야 한다는 것이죠.
신문사 갯수만 몇백개가 넘는데, 이건 거의 불가능하다고 생각했습니다.
헌데, 방법이 있더군요.
'네이버 뉴스 홈'이라는 플랫폼안에서 동일한 html 구조를 가진 기사들을 크롤링 하는 것입니다.
(엥 이게 도대체 뭔 소리야? )
네이버 검색창에 검색어를 입력하시면 아래와 같이 기사 리스트 들이 뜹니다.

2번째 기사를 보시면 '8분 전' 뒤에 노란색 하이라이트로 '네이버뉴스'라고 쓰여진 것을 알 수 있죠.
반면 1번째 기사는 그런것이 없습니다.
2번째 기사의 '네이버 뉴스'를 눌러보면
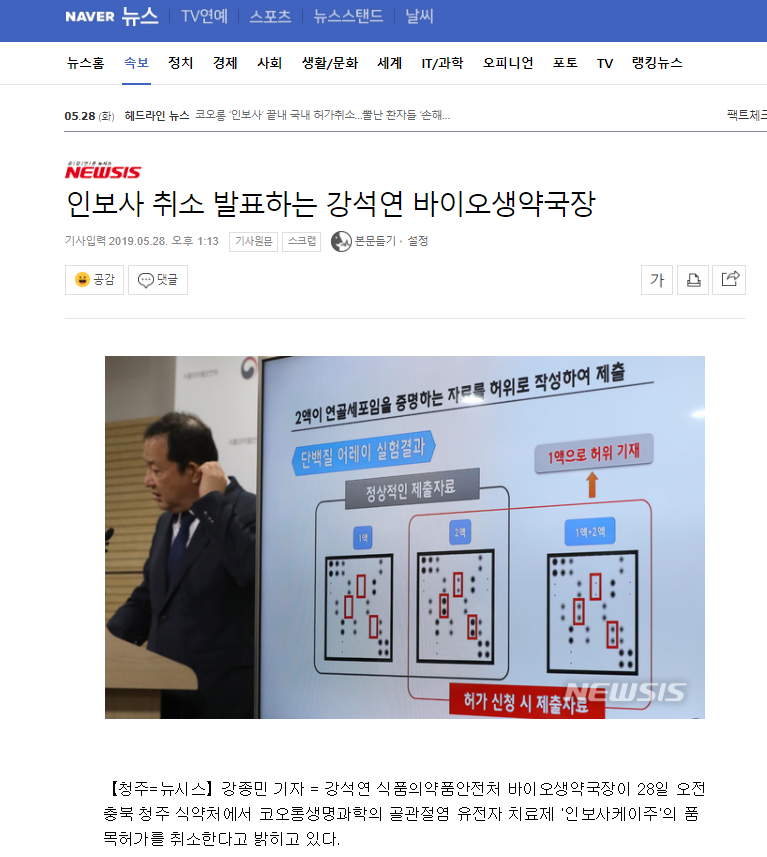
'네이버 뉴스 홈'에서 2번째 기사의 신문사인 뉴시스의 기사를 똑같이 보여주고 있는 것을 알 수 있습니다.
정리 하자면 이거입니다.
- 문제점 : 각기 다른 신문사 마다 다른 html 구조와 tag id값을 가지고 있어 크롤링 할 수 없다.
- 해결방안 : 동일한 html 구조를 가진 뉴스 플랫폼(=동일한 html구조로 뉴스를 모아놓는 곳)에서 신문기사를 크롤링 하자!
그 동일한 html 구조를 가진 뉴스 플랫폼이 바로 '네이버 뉴스 홈'인 거죠!
와우! 그럼 우리는 이제 저 '네이버뉴스' url을 타고 들어가서
beautiful soup로 네이버뉴스 기사 전문을 크롤링해오면 되는 겁니다!
하지만, 문제점이 몇가지 있습니다!
첫째,
'네이버 뉴스 홈'에 등록된 기사가 생각보다 많지 않다! ( = 크롤링 결과가 적을 것이다.)
원래라면,
1페이지에 10개의 기사들이 있다고 치면
내가 10페이지를 크롤링하면 100개의 기사를 크롤링 해오겠죠?
하지만, 우리는 네이버 뉴스 홈에 등록된 기사만을 크롤링 해 올 수 밖에 없기때문에
한페이지에 네이버 기사가 몇개냐에 따라
크롤링해오는 기사 갯수가 천차만별이 되는 겁니다.
(참고로 한페이지당 보통 0~3개 꼴인 것 같습니다.)
그니깐 10페이지 한다고 100개의 기사가 크롤링되는게 아니란 소리,
10개일 수도있고 20개일 수 도 있고 40개 일 수도 있고...
둘째,
연예 , 스포츠 ,날씨 뉴스는 크롤링 안됨
이건 문제점이라고 할 순 없지만 저도 처음에 몰라서 당황 했기에 설명하겠습니다.
연예뉴스 , 스포츠 뉴스, 날씨 뉴스는 아예 다른 네이버 뉴스홈에서 제공되고 있어서 이에 관련된 크롤러는 따로 만드셔야합니다.
(예를 들어 연예인 이름인 강다니엘을 크롤러에 키워드로 입력하시면 크롤링을 해올 수 없습니다.)
그 외 크롤링 가능한 주제들은 아래와 같습니다.

beautifulsoup 네이버 뉴스, git 네이버 뉴스 크롤링, naver news 크롤링,
naver 크롤링, python crawling, 네이버 뉴스 전체 크롤링, 네이버 뉴스 크롤링,
02. 크롤러 설명
<크롤링 할 것>
- 기사 제목
- 신문사
- 표준화된 날짜 (2019.01.01)
- 내용 전문
- 해당 기사 하이퍼링크
<프로그램 돌아가는 방식>
- 사용자 입력(페이지 수, 검색어, 검색 방식, 시작 날짜, 끝 날짜) def main
- 사용자 입력값 받아와서 def crawler 작동
- 만약에 하이퍼링크가 "https://news.naver.com"으로 시작하면 def get_news함수 작동하여 크롤링 할 것들 크롤링한다.
- 웹크롤링 결과 저장 ( 리스트 -> 메모장으로 저장 -> 메모장을 csv로 불러와서 -> 최종 엑셀로 저장)
** 참고로 저는 spyder 에디터를 사용했습니다!
03. 코드 설명
3-0. import할 라이브러리와 변수
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
RESULT_PATH = 'D:/python study/beautifulSoup_ws/crawling_result/'
now = datetime.now() #파일이름 현 시간으로 저장하기
requests, bs4 >> 크롤링을 위한 라이브러리
pandas >> csv파일을 불러오기 위한 라이브러리
datetime >> 최종 저장파일 이름을 현시각으로 저장하기 위한 라이브러리
RESULT_PATH >> 크롤링 결과를 저장할 폴더 경로 ! 꼭 확인해서 변경해줄것 !!
3-1. main 함수
def main():
maxpage = input("최대 출력할 페이지수 입력하시오: ")
query = input("검색어 입력: ")
s_date = input("시작날짜 입력(2019.01.01):") #2019.01.01
e_date = input("끝날짜 입력(2019.04.28):") #2019.04.28
crawler(maxpage,query,s_date,e_date) #검색된 네이버뉴스의 기사내용을 크롤링합니다.
excel_make() #엑셀로 만들기
main()사용자로부터 입력 값을 받아와 crawler함수로 넘겨주고
엑셀로 만들라는 지시를 한다.
3-2. crawler 함수
- 네이버 뉴스 홈에 등록된 기사인지 확인하고
- 맞으면 해당 url을 get_news에 보내고 리턴값(리스트 형식)을 메모장으로 저장하는 함수
def crawler(maxpage,query,s_date,e_date):
s_from = s_date.replace(".","")
e_to = e_date.replace(".","")
page = 1
maxpage_t =(int(maxpage)-1)*10+1 # 11= 2페이지 21=3페이지 31=4페이지 ...81=9페이지 , 91=10페이지, 101=11페이지
f = open("D:/python study/beautifulSoup_ws/crawling_result/contents_text.txt", 'w', encoding='utf-8')
while page < maxpage_t:
print(page)
url = "https://search.naver.com/search.naver?where=news&query=" + query + "&sort=0&ds=" + s_date + "&de=" + e_date + "&nso=so%3Ar%2Cp%3Afrom" + s_from + "to" + e_to + "%2Ca%3A&start=" + str(page)
req = requests.get(url)
print(url)
cont = req.content
soup = BeautifulSoup(cont, 'html.parser')
#print(soup)
for urls in soup.select("._sp_each_url"):
try :
#print(urls["href"])
if urls["href"].startswith("https://news.naver.com"):
#print(urls["href"])
news_detail = get_news(urls["href"])
# pdate, pcompany, title, btext
f.write("{}\t{}\t{}\t{}\t{}\n".format(news_detail[1], news_detail[4], news_detail[0], news_detail[2],news_detail[3])) # new style
except Exception as e:
print(e)
continue
page += 10
f.close()사용자 입력값을 받아와 url을 만든다.
여기서 url변수는 네이버에 키워드를 검색했을 때 기사 리스트들의 페이지들의
규칙에 맞게 만든 변수이다. (전 포스팅 참고)
|
for urls in soup.select("._sp_each_url"): |
"_sp_each_url" 라는 클래스이름을 가진 부분을 가지고 와서 urls라는 변수에 집어넣는다.


'_sp_each_url'은 요 '네이버뉴스'로 가는 하이퍼링크가 걸린 부분의 클레스명이다.
만약 urls 중에 href가 "https://news.naver.com"으로 시작하면
get_news 함수를 실행시켜 크롤링을 해온다.
| f.write("{}\t{}\t{}\t{}\t{}\n".format(news_detail[1], news_detail[4], news_detail[0], news_detail[2],news_detail[3])) |
get_news 함수를 통해 크롤링해 온 결과를 메모장에 입력을 한다.
이때 제목과 내용, 날짜, 신문사,링크 등 구분을 할 수 있게 사이사이에 tab을 넣는다. (tab = \t)
3-3. get_news 함수
- 네이버 뉴스 홈에 등록된 기사를 크롤링해오는 함수
def get_news(n_url):
news_detail = []
breq = requests.get(n_url)
bsoup = BeautifulSoup(breq.content, 'html.parser')
title = bsoup.select('h3#articleTitle')[0].text #대괄호는 h3#articleTitle 인 것중 첫번째 그룹만 가져오겠다.
news_detail.append(title)
pdate = bsoup.select('.t11')[0].get_text()[:11]
news_detail.append(pdate)
_text = bsoup.select('#articleBodyContents')[0].get_text().replace('\n', " ")
btext = _text.replace("// flash 오류를 우회하기 위한 함수 추가 function _flash_removeCallback() {}", "")
news_detail.append(btext.strip())
news_detail.append(n_url)
pcompany = bsoup.select('#footer address')[0].a.get_text()
news_detail.append(pcompany)
return news_detail- crawler 함수로 부터 n_url을 받아서 크롤링을 해온다.
- 결과를 new_detail이라는 list로 저장하여 리턴 한다.
3-4. execel_make 함수
def excel_make():
data = pd.read_csv(RESULT_PATH+'contents_text.txt', sep='\t',header=None, error_bad_lines=False)
data.columns = ['years','company','title','contents','link']
print(data)
xlsx_outputFileName = '%s-%s-%s %s시 %s분 %s초 result.xlsx' % (now.year, now.month, now.day, now.hour, now.minute, now.second)
#xlsx_name = 'result' + '.xlsx'
data.to_excel(RESULT_PATH+xlsx_outputFileName, encoding='utf-8')
위에서 만든 메모장 파일을 csv 형식으로 불러와서 data 변수에 저장한다.
data 변수에 columns명을 주고 excel 파일로 저장한다.
이때 이름은 datetime 라이브러리의 now함수를 사용하여 현시각으로 저장한다.
04. 실행 결과

코드를 실행하고
크롤링할 입력값들을 입력해 줍니다.
위에서 설명했듯이 네이버 뉴스 홈에 등록된 기사가 생각보다 많지 않으니
많은 크롤링 결과를 얻으려면
최대 출력할 페이지수를 크게 적어주세요! (대신 그만큼 크롤링하는데 시간이 좀 더 소모됩니다)
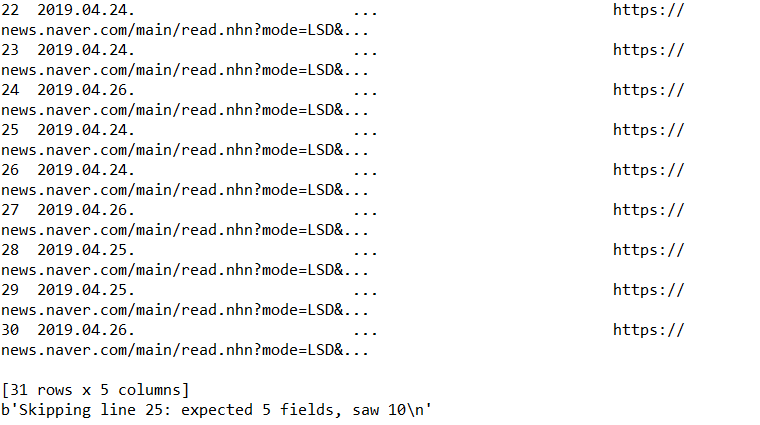
크롤링이 성공!
31 rows x 5 columns 가 엑셀로 저장되었네요.
10페이지를 크롤링했는데 결과가 31개뿐...

크롤링 결과 저장경로 (RESULT_PATH) 로 가보면 파일이 2개 있을 겁니다.
오늘 포스팅한 크롤러가
contents_text.txt 파일로 저장했다가 엑셀 파일로 저장하기 때문에 파일이 2개입니다.
우선 txt파일 먼저 열어봅시다.

텍스트 파일을 열어보니 날짜와 신문사 내용 링크가 tab을 기준으로 구분이 되어있는것을 알 수있습니다.
한줄로 되어있어서 기사 전문이 아닌걸로 착각할수 있으나 전문 맞습니다!
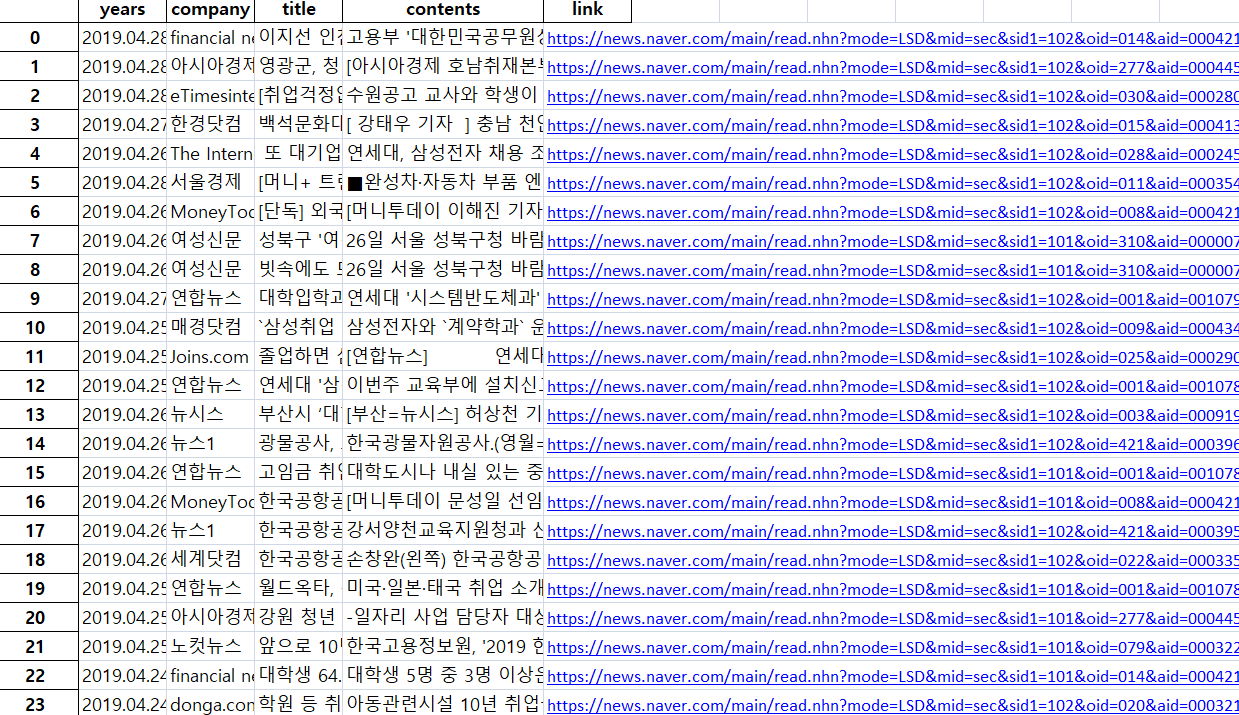
엑셀파일도 문제 없네요 ㅎㅎ
코드 전체는 github에 올려 놨습니다.
아래 링크로 들어가서
'Clone or Donwload' - 'Download Zip ' 을 눌러 다운 받으세요~
https://github.com/sbomhoo/naver_news_crawling_perfect
sbomhoo/naver_news_crawling_perfect
네이버 뉴스 전문 크롤링. Contribute to sbomhoo/naver_news_crawling_perfect development by creating an account on GitHub.
github.com
beautifulsoup 네이버 뉴스, git 네이버 뉴스 크롤링, naver news 크롤링, naver 크롤링, python crawling, 네이버 뉴스 전체 크롤링,
네이버 뉴스 크롤링, 뷰티풀수프, 뷰티플수프 크롤링, 웹 크롤링, 크롤링, 파이썬, 파이썬 네이버 크롤링, 파이썬 크롤링
'공부 > Python' 카테고리의 다른 글
| [점프 투 장고] views.py 작성했는데, 404에러 뜬다면.. (0) | 2021.08.31 |
|---|---|
| 파이썬 / 크롤링 참고 사이트 주소 (0) | 2019.02.13 |
| [python] beautifulsoup을 이용해 네이버 뉴스 리스트 크롤링을 해보자! (77) | 2019.02.07 |